HashMap 前世今生
要了解 HashMap 首先要先了解哈希表这种数据结构。哈希表是根据关键码值进行访问的数据结构。我们可以类比成现实生活中的电话本,如图所示。
假设这个人交际能力特别强,他保存了很多人的电话,这个电话本就会很厚,当你想要查找某个人的电话时,就会非常费时。因此我们可以根据姓的首字母,分类排序,把张三放到 Z 里面,李四放到 L 里面,以此类推。通过这种方法,我们得找人效率就会大大提高。
我们已经按照刚才的方法分好类了,可以看到 Z 分类下面有多个名字,我们把这样一组称作哈希桶,把 Z 叫做** 哈希值,整个电话本就是一个哈希表,我们还把一个哈希值对应多个数据,这种现象叫做哈希碰撞。**
使用哈希表的好处就是 O(1) 的平均查找,插入和删除时间。致命缺陷就是哈希值的碰撞(哈希碰撞)。在 Java 世界中对于 哈希表的实现就是 HashMap。
Java 7中的 HashMap
经典的哈希表实现:数组 + 链表,其中链表采用头插法(每次有新元素都放到第一位)
HashMap 构造方法
查看 HashMap 源代码,它默认的初始大小是 1 << 4 ,表示位运算,等价于 1 * 2^4 即等于16,因此默认大小就是16。且注释中规定容量必须是2的幂。

源代码中定义了默认的 DEFAULT_LOAD_FACTOR (负载系数)是 0.75

默认的构造函数,把默认的初始容量,以及默认的负载系数当参数传递给重载的构造函数。注意事项:当我们调用 HashMap 的构造函数时,哈希桶并没有开辟出来,只有第一次往里面 put 元素进去的时候,空间才会开辟出来,这样避免了空间浪费。
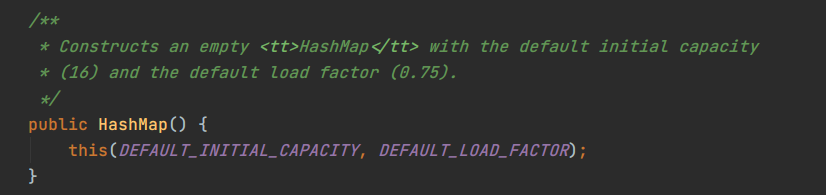
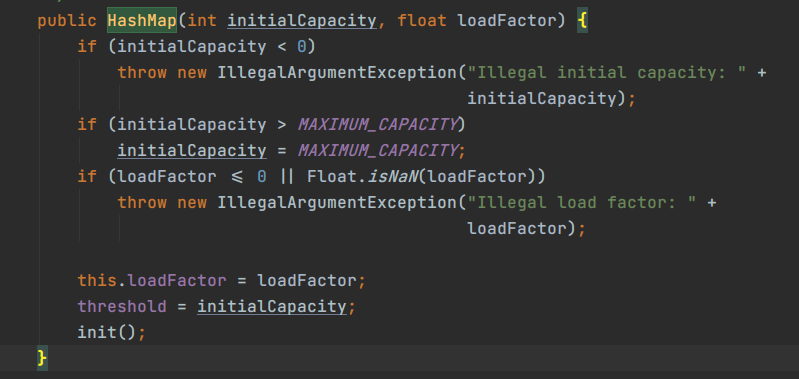
HashMap put 方法
inflateTable 方法
put 方法首先是一个判断,判断表是否是一个空表,如果是就调用 inflateTable 方法,把 threshold 参数传进去。因为使用 HashMap 构造方法时,以及将初始化容量赋值给 threshold,所以他的值就是容量的值。
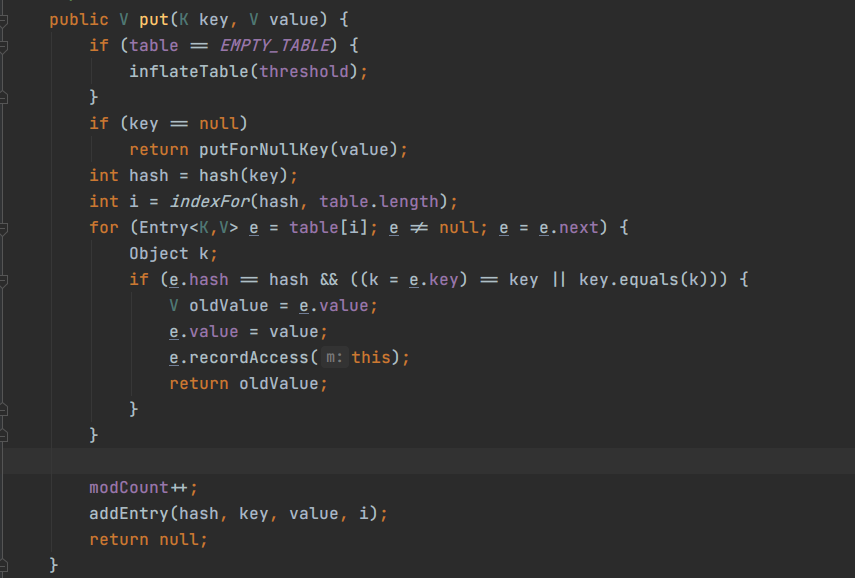
执行 inflateTable 方法,我们可以看到该方法对于我们传来的容量值进行了一个向上取2次幂的操作。前面注释规定容量必须为2次幂,当我们自定义容量不为2次幂时,他就帮我们向上转为2次幂。例如:我们定义初始容量为17,他就会帮我们转化成32;初始容量定为5,帮我们转成8,这样就达到了容量必须为2次幂的要求。
hash 方法
hash 方法把我们输入的 key 值,通过他特定的算法,返回一个 int 值。既然我们知道了元素对应的 hash 值,那么我们应该如何设计一个映射,把元素放到它对应的哈希桶里呢?就像「张三」对应 “Z” 这个桶一样。
数据结构课程中提到过取模运算,我们把 hash 值通过取模运算得到的结果,跟哈希桶编号进行比对,一致就放在该哈希桶里。但是这样做存在两个缺点:由于 hash 值可能得到负数,负数取模运算还是负数,而哈希桶编号是正数。因此遇到 hash 是负数的情况,需要转化成正数;其次,使用取模运算较慢。
让我们看看源代码中 indexFor 方法,是如何设计其中的映射关系的。
indexFor 方法
我们可以在 put 方法中找到这一行代码
1 | |
其中把 hash 值和表的长度(表的长度为哈希桶个数,即为初始容量大小)当做参数,调用 indexFor 方法计算出该元素对应哈希桶的编号。
我们点进去查看具体的方法实现
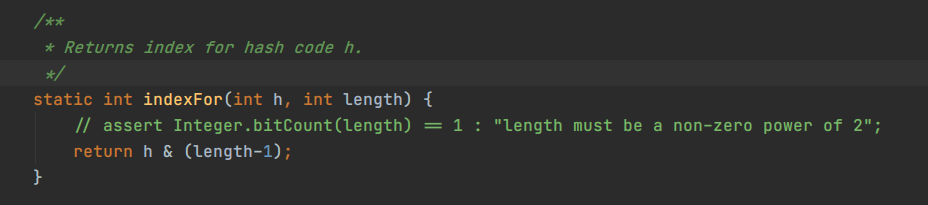
如图所示,他把 hash 值 length - 1 进行了按位与运算,得到的结果就是索引坐标。它这样做的目的在于提高效率,与运算比我们刚才说的取模运算要快很多。
为什么容量必须是2的幂呢?我们前面一直说到容量必须是2的幂,是因为方便这里进行与运算。2的正数次幂的二进制值首位是1其它全部都是0,例如:2^3 = 1000,2^4 = 10000。因此当他们再减1时,得到的值都会变成1,例如:2^3 -1 = 111,2^4 -1 = 1111。使用这种都是1的数与 hash 值进行与运算,得到的坐标就与 hash 值有关了。假设我们初始容量是 2^4,减1之后与 hash 值进行按位与运算得到的坐标如下。
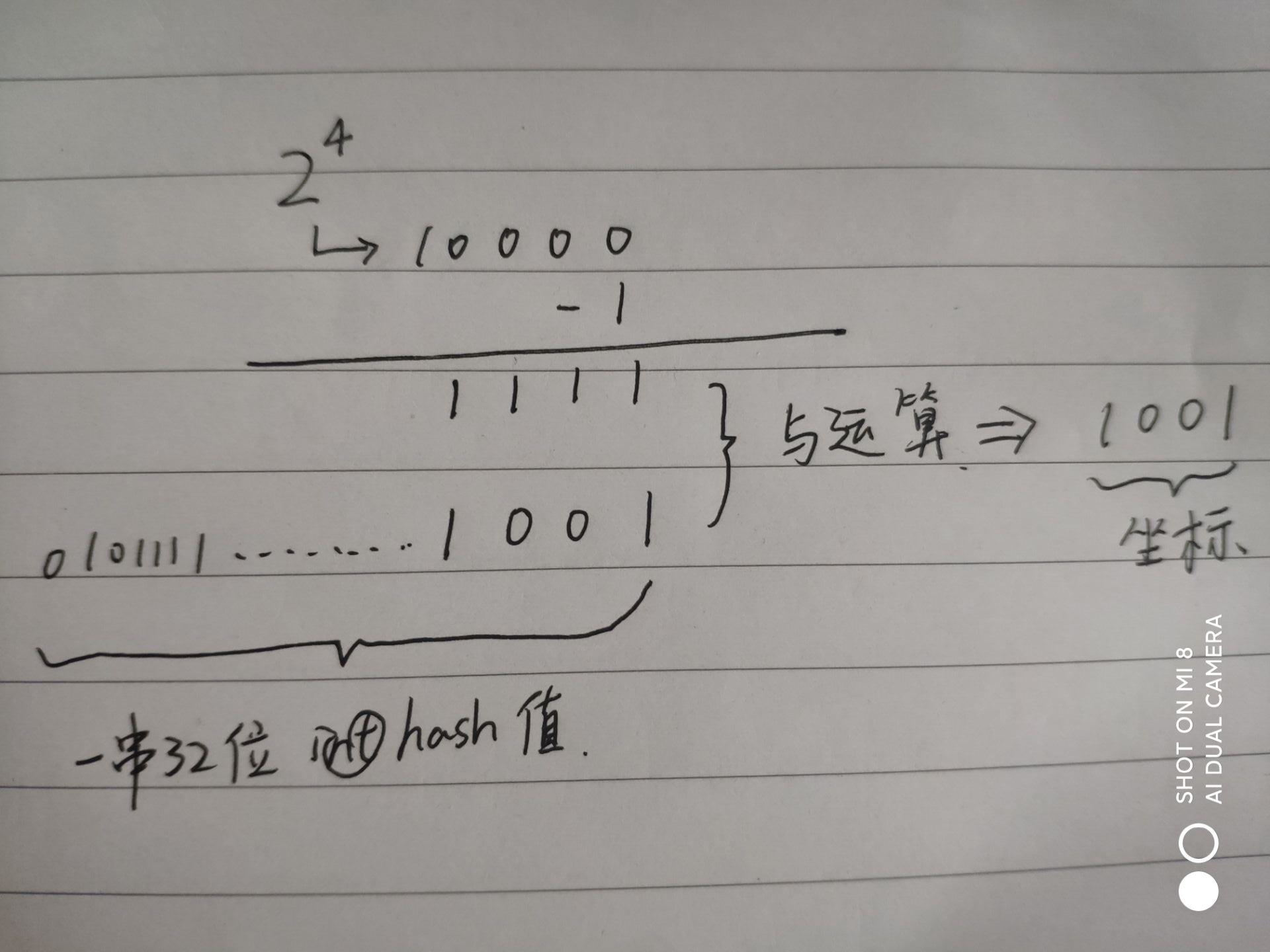
假如我们不用2次幂来设定容量,我们设定容量为7,与 hash 进行与运算得到的坐标如下。你可能会想,这样不是也可以得到坐标吗?这样可以得到没错,但是会发现有些桶永远是空着的。如下图所示,当我们的 hash 值无论为多少,和110进行与运算后,最后一位一定是0,因此必然得不到101,001,011坐标,所以哈希桶坐标为5,1,3的桶永远都是空着的。
addEntry 方法
接着 put 方法往下看,addEntry 方法往指定坐标的哈希桶里面添加元素。具体的实现方法如下
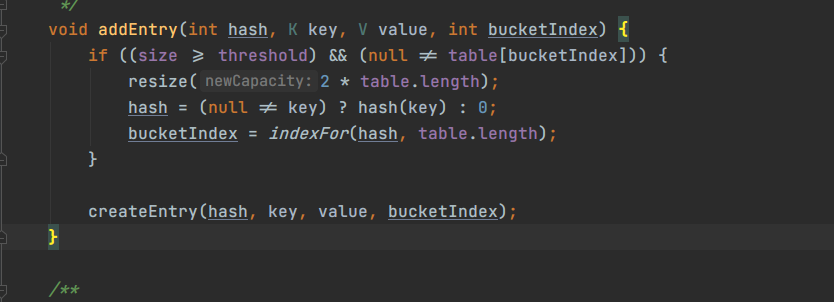
可以看到,添加元素前前。进行了一个判断,当哈希桶中的元素 size 大于等于 threshold(初始化容量 * 负载系数,即默认的为 16*0.75 = 12),并且指定的桶不能为空时,执行 resize 操作,新的容量是原来容量的2倍。
HashMap 扩容操作
以下是 resize 方法的具体实现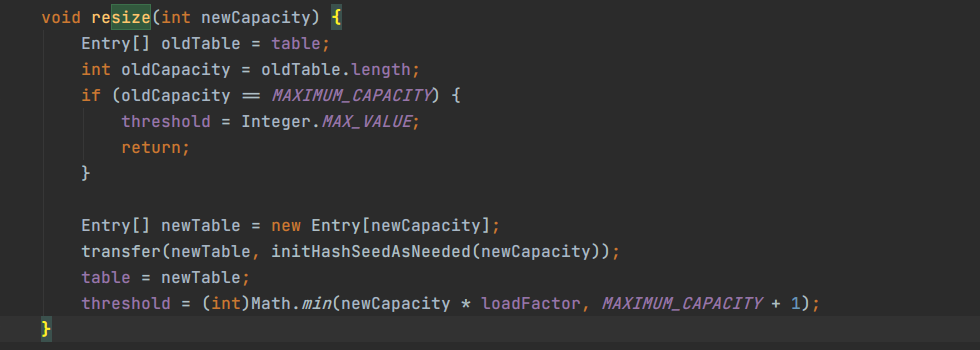
扩容的时候容量为原来的2倍,然后把原来所有的元素全部迁移到新的中去。元素的迁移过程使用了 transfer 方法
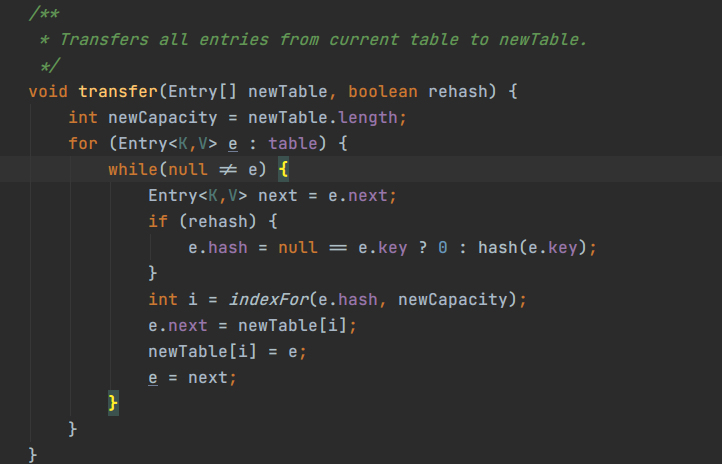
transfer 方法遍历旧表中每一个桶里面的元素,重新进行 hash 运算,得到新的值,再把该元素放到新表中,对应的哈希桶中。
缺陷
- 在多线程环境中,java7中 HashMap 的实现容易成环,形成死锁,详见文章。
- 可以通过精心构造的 HTTP 请求,使得所有元素都落入到同一个桶中,引发 DOS。
Java 8中的 HashMap
实现:数组 + 链表/红黑树,其中链表采用尾插法(每次有新元素都放到最后一位)
链表转为红黑树
java 8中使用了新的数据结构,红黑树。但并不全是红黑树,原来的链表也是存在的。java 8中给链表中的元素设定了一个阈值,大于等于这个阈值就会转化成红黑树,如下图所示。
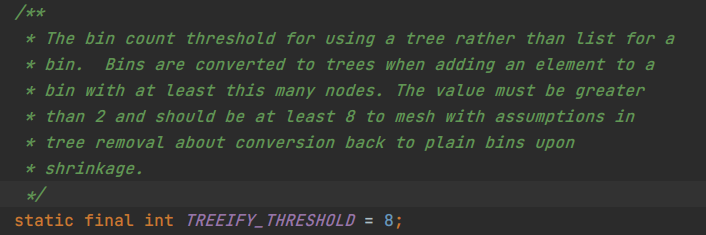
java 8 设定这个树形化的阈值 TREEIFY_THRESHOLD 为8,当链表中元素个数大于等于8时,就会转化为红黑树。
那么为什么要数量大于等于8时,才转化为红黑树呢?这个在源代码中也有解释,下图截取自 java 8的源代码注释。
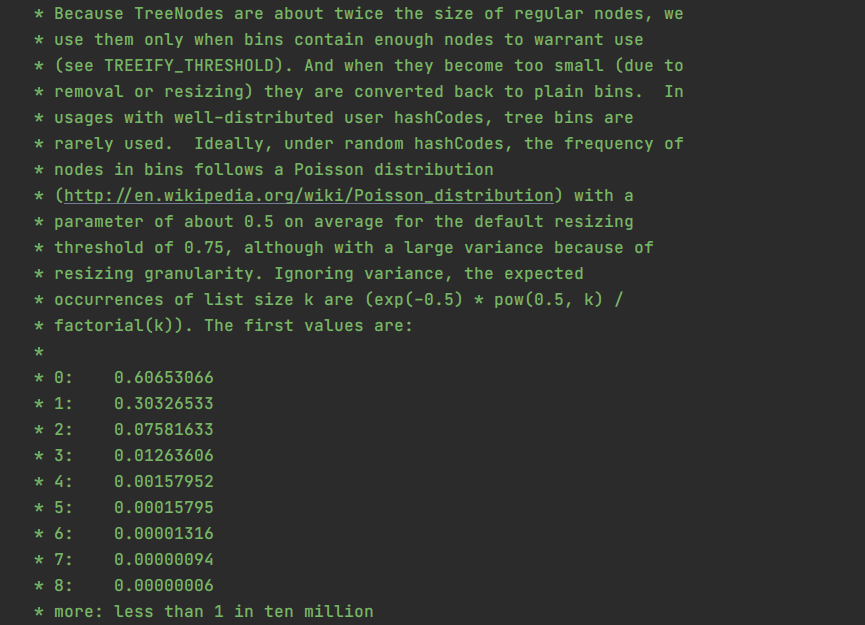
通过图中的解释可以知道,我们的 hash 值是遵循泊松分布的。每个桶中有0个元素的概率是 0.60653066,以此类推,可以看到桶中有8个元素的概率是 0.00000006,超过8的概率小于十万分之一,这个概率已经非常小了。因此树形化阈值才会设定为8。
扩容操作
java 8在原来 HashMap 扩容的基础上改进了一点,原来的 HashMap 扩容之后不保证顺序,java 8则保持了扩容之前与之后的元素插入顺序一致,这样降低了线程出现问题的概率,但还是没有彻底解决线程安全问题。在多线程环境下请使用 ConcurrentHashMap。
java 7中旧表中的元素要重新进行 hash 运算得到 hash 值,再把它放到新表中,而 java 8对这一方法进行了优化。
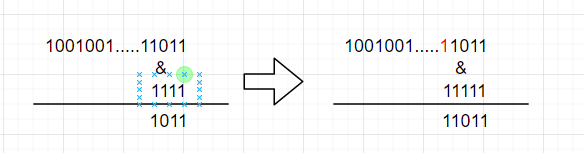
假设图左边的初始容量为16,扩容之后诚意2得到的容量为32。 1001001......11011 这个哈希值,计算出它对应的坐标,因此与16 - 1的二进制,进行与运算,得到1011。而扩容到32时,按照原来的方法重新计算坐标得到 11011。从中我们可以发现,扩容之后,hash 值由原来的4位参与运算,变成了5位,我们把新增加的那一位称作高位,其他不变的称作低位。对应图中的高位就是标红的1,低位就是1011。进而我们也可以知道,扩容之后元素对应的坐标他的低位是不会变的,新坐标就取决于高位的值。
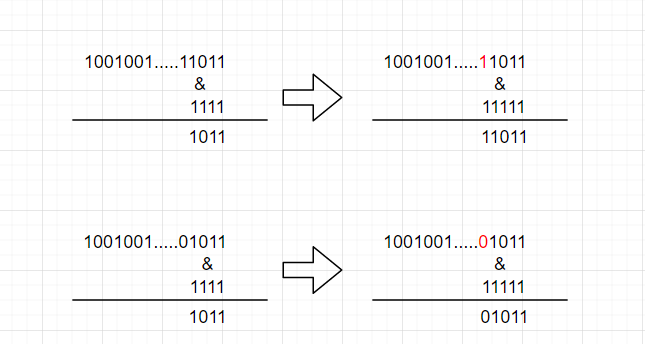
如图,高位为1时,原来的坐标 1011对应十进制是11,扩容之后新坐标 11011对应十进制是27,坐标发生了改变。高位为0时,原来的坐标还是1011,新坐标也是1011,新坐标与原来坐标相等。因此可以总结规律:高位为0,扩容之后新旧坐标相等;高位为1,新坐标 = 1 + 旧坐标。
java 8中 HashMap 就是根据这一规律进行扩容,这样计算新坐标比 java7重新进行坐标运算要快上不少。