字符串与编码
我们都知道,在网络通信和存储的都是字节流,都是一大串的 0 和 1。不知道大家有没想过,存储既然是 0 和 1,为什么我们看到得都是一个个字符,汉子,英文?是不是计算机在背后偷偷的把字节转化成我们人类能看懂的语言?答案是肯定的。
字符集相关概念
既然计算机帮我们把字节转成人类的语言,那么肯定存在着一种映射关系「字节 –> 人类语言的映射」,我们把这种关系称为字符集。把字节转化成人类看懂的字符,这一过程称为编码,反之称为解码。
假如世界都用同一份字符集,同一种编码和解码方式那么就不会存在我们常见的「乱码」问题了。但正是因为世界多样性,也导致了字符集的多样性,每个国家语言不同,所使用的字符集,编解码方式也可能不同。
假如我们把阿拉伯数字看作字节,把不同语言的翻译看做编解码方式。因此,1,2,3 翻译成汉字就成了一,二,三;翻译成英文就成了 one,two,three。假如,本应该使用中文编码的字节,却使用了英文编码,这就会让没有学过英语的人看不懂,不懂 one,two,three 是什么,对于他们来说这就是乱码。
字符集 Unicode
在字符集群魔乱舞时代,有人站了出来。他把所有的地区性编码方案废弃,重新搞了一个包括了地球上所有文化、所有字母和符号的编码 Unicode。其中 uni 是英文前缀,表示「单一,一个」,因此 Unicode 的字面意思也很好理解,百度百科上翻译成「统一码,也叫万国码、单一码」。
Unicode 的设计非常的简单:从一个数字映射到一个字符。图中简单地演示了 unicode 的映射关系,实际上的对应关系并非如此。

图中所示,把左边的数字编号称作码点(code point)。
Unicode 数据类型
现在换位思考下,如果让你来设计 Unicode 码表,你会用什么数据类型来存储上面的数字编号呢?
现在来对比下这些数据类型关系
1 | |
很显然 byte 不合适,256个数,存中文都不够。short 存中文可能勉强够用,但是这还要包含其他国家的文字啊,加起来肯定不够用。int 42 亿个,足够全世界的文字使用, 因此选用 int 类型,实际上 Unicode 也是这么做的。
缺陷
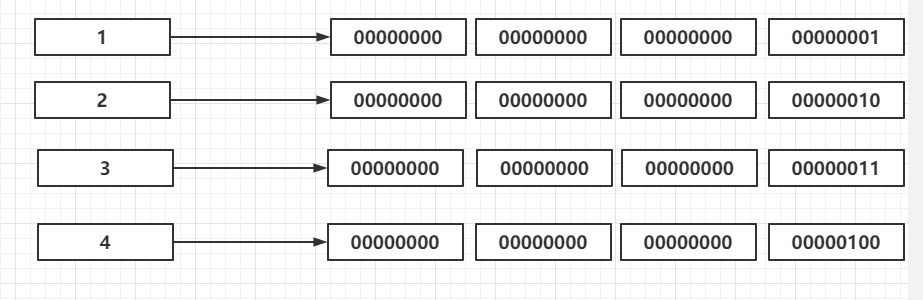
上面提到为了包含全世界所有的文字,Unicode 使用了 int 类型。int 4个字节,对于编号在前面的字符,就会造成空间浪费。例如编号为 1 的字符,把编号转换成字节就变成 “00000000 00000000 00000000 00000001”,我们会发现前三个字节都是 0,这样造成了空间浪费。本来一个字节就能表示的编号,硬是多占用了3个字节,编号靠后的还好,靠前的大多都浪费流量,浪费空间。
如图我们把前四位编码成 4 个字节,编码后的前三个字节都是 0。更何况Unicode 兼容了 ASCII 码表,前128 位都是常用的一些字符,本来字母 “a” 只需要占用一个字节,经过 Unicode 编码后需要占用 4 个字节,不利于传输和存储。
常见的两种编码方案:UTF-8,UTF-16
正是因为 Unicode 对于靠前的码位太占空间了,所以就有了 UTF-8,UTF-16 等编码方案,用来解决空间占用问题。其实我们也很容易想到一种解决方案:把常用的字符用一个字节存储,不常用的用多个字节存储,这样就避免了 Unicode 缺陷
UTF-16
UTF-16 根据码位所处的范围进行不同编码。
U+0000 至 U+D7FF 以及从 U+E000 至 U+FFFF 的码位
第一个 Unicode 平面(码位从 U+0000 到 U+FFFF )包含了最常用的字符。只要处于这个范围内,UTF-16 就使用两个字节存储它。我们的汉字基本上都是处于该范围,因此在 UTF-16 中,汉字大多都是两个字节。
U+10000 至 U+10FFFF 的码位
当处于码点处于该范围时,UTF-16 就使用 4 个字节进行存储。因此,UTF-16 将常用的字符用 2 个字节存储,不常用的用 4 个字节存储,相比 Unicode 空间节省了不少。
一个简单的 UTF-16 编码过程
1 | |
「周」字的码位,转成 16 进制得到 5468,然后判断所属范围,很显然属于上面的第一种范围,因此「周」字需要两个字节存储 54 68。我们可以在程序中打印出来 System._out_.println('\u5468')。
BOM
两个字节代表一个字符,在存储传输过程中存在着顺序问题。拿刚才的「周」字举例,虽然我们认为在传输过程中都是按照 54 68的顺序,但实际并非如此。在有的系统他是反过来传输的 68 54,为了解决这个问题,在文件的开头加入了几个不可见的字符,来声明字节顺序。这几个特殊字符称作 BOM(byte order mark),即字节顺序标记。
上面的字节存储传输的方式,也有专业的名称。这个在编码中叫做大端(Big Endian 简写 BE)和小端(Little Endian 简写 LE)。在很多文本编辑器也有出现,比如我在使用的 Notepad2,就支持 UTF-16 LE BOM 和 UTF-16 BE BOM 编码方式。
顺带一说的是,Java 程序内部的存储编码方式就是 UTF-16。
UTF-8
先说一个结论:如果没有意外,所有的编码方案都改成 UTF-8,UTF-8 是对多语言支持最好的一种解决方案。在 Mac/Linux 默认编码就是 UTF-8,由于历史原因,Windows 默认的中文编码是 GBK。
UTF-8 是一种可变长的编码方式,那它是怎么做的呢?他对所有的码表进行分区,第一个分区占用一个字节,第二个占用两个字节,以此类推,最多支持到 6 个字节。UTF-8 兼容了 ASCII 码表,因此 ASCII 码表的字符在UTF-8 中占用一个字节,属于下面第一行的范围。我们使用的汉字,属于第三行的范围,因此汉字在 UTF-8 中编码占 3 个字节。下面展示了从 1 到 4分区范围。
1 | |
例如:「周」字的码位 21608,转换成 16 进制 5468 属于第三行的范围,根据他的编码规则会生成 3 个字节,编码过程如下:
1 | |
不知道大家有没思考过一个问题:UTF-8 编码之后,计算机怎么知道该读几个字节?例如上面的 11100101 10010001 10101000计算机怎么知道这 3 个字节是一起的,而不是分 3 次读单个字节呢?
其实仔细观察分区之后的模板就能发现端倪,第一分区首字节的第一位是 0,第二分区首字节前两位两个 1,第三个分区有三个1,计算机就是根据这个特点来进行读取的,当读到第一个字节前几位有几个 1 就读几个字节。刚才的「周」第一个字节有三个 1,因此计算机就连续读三个字节。由于这一特性,UTF-8 是不需要 BOM 的,但是 windows 的记事本默认都会加上 BOM,不支持不带 BOM 的编码(最近好像支持了),UTF-8 带
这个模板是如何设计生成的呢?编解码的算法是如何实现的呢?这里不展开(主要是我也不会),维基百科搜 UTF-8 就好了(推荐),或者访问他人博客,了解相关内容。
GBK
GBK(国标扩展) 字符集,简称国标扩。GBK 完全不鸟 Unicode 标准,对于中文统一采用 2 个字节编码,因此在 GBK 编码中汉字是占用两个字节。
乱码的来源也与 GBK 有关,如果文件是用 Unicode 字符集编码,而你却使用 GBK 去解码,就会导致乱码问题。比如「周」字,在 Unicode 的码位是 21608,而在 GBK 的码位是 55004,通过去查 GBK 码位 21608 对应的字符就不是 「周」这个字了。
现在互联网的主流都是使用 UTF-8 编码,GBK 只适合给国人使用的网站上,局限性太大。
简单的测试
测试 1:一份用 UTF-16 编码的全英文文本,更改编码方式为 UTF-8,存储占用会减少吗?答案是会,因为 UTF-16对英文用两个字节编码,而 UTF-8 中英文属于第一分区,因此占用一个字节,所以改为 UTF-8 之后差不多减少一半的空间占用。
测试 2:一份用 UTF-8 编码的全汉字文本,更改编码方式为 UTF-16,和 GBK,存储占用会发生什么变化?答案是都会减少占用,GBK 对中文是两个字节编码,UTF-16 对大多数中文也是两个字节编码,而 UTF-8 对中文是 3 个字节编码,因此占用会减少。
一些小感悟
写这篇博客的时候,遇到很多问题,本来只是想写 UTF-8 和 Unicode 的,越往下写的时候发现还有很多东西没有掌握,因此一边消化(幸运的是消化难度还能接收),一边写了这篇博客,终于是把字符,乱码相关的搞明白了。
当我感叹 UTF-8 编解码算法的时候,搜了下发明者 Ken Thompson,这么多优秀的作品都与他有莫大的关联,Unix,正则,UTF-8,以及现在火热的 Go 语言,还获得图灵奖,我也只能顶礼膜拜。了解的越多,发现了计算机领域基本上所有伟大的东西,都是那么一小撮人发明的。如图是 Ken Thompson 相关的简介,想具体了解可以去维基百科搜索。
