Stream
什么是 Stream 流
流就相当于工厂的流水线工作,传送带上是一件件产品,而传送带周围是一些工人。有的负责把挑出次品,把它放到其他另一条流水线中重新加工,有的负责根据产品颜色进行收集,等等。如下图所示。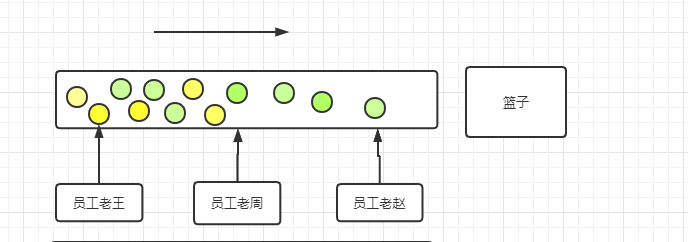
三个员工对传送带上的产品进行操作,老王负责收集把黄色产品挑出,老周负责把产品按先后排序,而老赵负责把残次品挑拣出来,拆开零件放到新的床送带中,继续加工。传送带的终点就是篮子,产品都流向篮子里面。
流的操作就是如此。在没有流之前,我们要自己从一堆产品中找到残次品很难。但是我们有了流之后,我们有了流水线,有了工人,我们就可以让工人帮我们收集,让他们来处理,我们只是充当老板的角色,下达命令即可。在 Java 的流 (Stream) 中,我们只需要使用一些命令,剩下的交给程序本身去执行。这样做既减少了代码量,又能高效完成我们的需求,真是两全其美。
在上面的过程中,我们把老王和老周,以及老赵操作叫做中间操作。因为他们并没有把产品收集起来,他们只是把其他不合格的产品过滤挑出,产品最终都是到篮子里面。但是你装产品不一定是用篮子,你也可以使用箱子,等其他容器。我们把使用这些容器装产品的操作称作终结操作。在 java 中,中间操作就是返回为 Stream 的操作,终结操作就是返回非Stream 的操作。下面会详细讲解。
Stream API
创建 Stream
- Collection.stream()
- Stream.of()
- String.chars()
- IntStream.range() 等
Stream 中间操作
- filter 按照输入的条件,过滤流中的元素
- map
- sorted 对流中的元素排序
Stream 终结操作
- forEach 遍历流中的元素
- count / max / min 统计元素个数 、最大元素、最小元素
- findFirst / findAny 找到第一个元素、随机找一个元素
- anyMatch / noneMatch 是否有匹配的元素、没有匹配的元素
- collect 等
从方法名中我们就能了解它的用处,更为详细的 API 操作可以查看 Stream 源代码。
Collector 操作
Collector 操作是 Stream 中最强大的操作,他就是我们上面例子中提到的「篮子」「箱子」等。它具有以下 API
- toSet / toList / toCollection
- joining()
- toMap()
- groupingBy()
通过这些 API 操作,使得我们能将流中的元素收集起来
下面通过一些实际案例,加深对 Stream 的理解。
案例1
1 | |
现在有个需求筛选出年龄大于等于60的用户,然后将他们按照年龄从大到小排序,将他们的名字放在一个LinkedList中返回。我们可以使用 Stream 写出如下代码
1 | |
解析:要使用 Stream 首先就需要创建它users.stream(),根据要求筛选出年龄大于 60 的用户 filter(user -> user.age >= 60),然后使用 sorted 对筛选后的用户按照年龄排序。由于我们要返回的是一个字符串列表LinkedList<String>,而我们 Stream 中的元素都是对象类型,因此我们使用 map(user -> user.name),把User 映射成 String 类型,这样 Stream 中的元素都是用户的名字了。最后,使用 collect 操作将用户的名字收集成一个 Linked ,这样就解决了我们的需求。
通俗解释:我们作为老板,我们要创建一条流水线,然后安排工人在流水线旁边进行操作。安排员工老赵把用了60年以上的产品,筛选出来。筛选完后,安排老周按使用时长进行从大到小排序。排序之后,安排老王把可用的零件拆下来,最后用一个篮子收集这些可用的零件。
案例2
统计一个给定的字符串中,大写英文字母(A,B,C,…,Z)出现的次数。例如,给定字符串”AaBbCc1234ABC”,返回6,因为该字符串中出现了6次大写英文字母 ABCABC
1 | |
解析:String 类型创建流 str.chars(),然后使用 filter 进行过滤操作,过滤出大写字母 filter(Character::isUpperCase),接着对过滤出的字母进行统计,完成需求。
更多关于 Stream 操作 demo点击这里
并发流
可以通过并发提高互相独立操作的性能。
互相独立操作指的就是,操作相互之间不影响。例:1个人割麦子需要10天,那10个人割相同面积的麦子就只需要1天。
非互相独立操作就像女人生孩子,1个女人十10个月生1个孩子,但是10个女人并不是一个月就能把孩子生出来。
在正确使用的前提下,可以获得近似线性的性能提升。要使用并发流我们可以使用 parallelStream()创建并发流。或者在原有流的基础上,使用 parallel() 方法将流转化为并发流。
使用一个简单的案例来使用并发流,统计 1 到 100万之间的质数个数 。原始的 Stream 写法如下
1 | |
并发流写法
1 | |
因为统计个数属于互相独立操作,就像两个人数羊群有多少只绵羊一样,两人分别数自己区域的羊,然后再加起来汇总。
对于并发流来说,使⽤要⼩⼼,性能要测试,如果你不知道⾃⼰在做什 么,就忘了它吧。对于详细的操作可以参考《Effective Java 第三版》42-48节。