JVM 基本结构
谈起 JVM 第一印象就是「八股」,毕竟正经人谁学 JVM 啊。当我深入学习,了解了相关原理后,真令人大呼过瘾。
了解 JVM 并不会让你更快的 CRUD,对大部分工作没有实质性的帮助,但这是成为高级程序员的第一步。
JVM 初识
JVM 全称是 Java virtual machine 即 Java 虚拟机。JVM 是抽象(虚拟)计算机,它定义了一系列规范,因此他有很多实现,如:HotSpot,Eclipse OpenJ9 等等,最常使用的应该就是 Oracle 的 HotSpot。
JVM 存在的意义就是抹平所有平台和操作系统的鸿沟。它就像是一个在不同平台提供的翻译官,当用英语和它对话时,他翻译成自己「国家」的语言并执行。这就是为什么在 Windows 下编写好的代码能够在 Linux 等其他系统运行的原因。
代码编译执行过程如图
程序员使用像 Java,Kotlin,Scala ,Groovy 等高级语言进行编码,编译成 JVM 能识别的语言。JVM 识别并进行「二次编译操作」,将它翻译成对应的平台语言。
日常编码所做的仅仅只是用高级语言编写一份「说明书」,说明书如何编译成中间语言,这就是高级语言编译器做的事了,当然也可以自己去实现一个编译器,嗯。。至少我目前没有这个能力。
JLS
Java 语言规范 Java Language Specification, 定义了 Java 编程的语法。比如 Java 中的关键字信息 class、public 等等,都是在 JLS 规范下,完成 Java 代码的开发。
JVMS
Java 虚拟机规范 Java Virtual Machine Specifiction,定义了字节码如何在 JVM 中执行,仅此而已。
JVM 堆 (Heap)
堆是 JVM 中非常重要的区域,所有的「对象」都在堆上分配,它是个无情的对象生产机器,只负责生产,不负责销毁。
堆为我们创建了对象,但是在代码中操作与访问对象实际上都是在操作对象的地址或者引用。
来看个非常简单的代码,以此来演示堆中发生了什么
1 | |
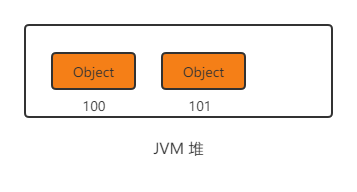
首先堆内存中创建了一个对象(假设对象地址为 100),然后将该对象的地址赋值给 obj 变量,可以想象有一条线将 obj 和 对象 100 连接起来。
接着,堆内存中又创建了一个变量 101,然后将该对象地址赋值给 obj,此时 obj 和对象 101 连接起来了。这就是堆所做的一切。
很显然,上面的例子对象 100 还是存在堆中,他并没有消失,他还在等有缘人「联系」它。
这样就会存在一个问题,「无人问津」的对象越来越多怎么办?这就涉及到 GC 了,GC 会根据相应的算法来判断对象是否需要回收销毁,因此暂时不需要操心,后续提供 GC 的讲解。
当然堆中产生的对象太多,大量占用堆内存,导致内存溢出,常见表现为 OOM (Out Of Memory) 异常。当代码出现该异常时,就应该关心,代码是否产生了大量不必要的对象,谨慎的检查代码。
JVM 栈(Stack)
当我们用 IDEA Debug 如下代码,可以看到在 IDEA 界面底部,多了一些信息。
1 | |
在我的调试器中表现形式如下:
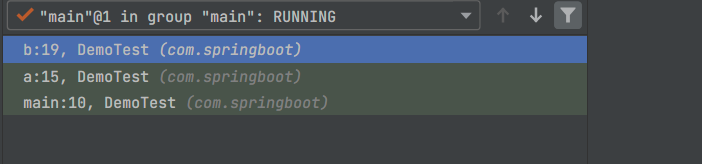
从 main 方法到 b 方法,中间一系列调用都称作「栈」或「方法栈」,其中每一次方法调用称作「栈帧」,如图中的 main,a,b。
不知你是否思考过,为什么代码的调用形式会是这样?无论你是否好奇过,现在我来分析下代码执行的过程。
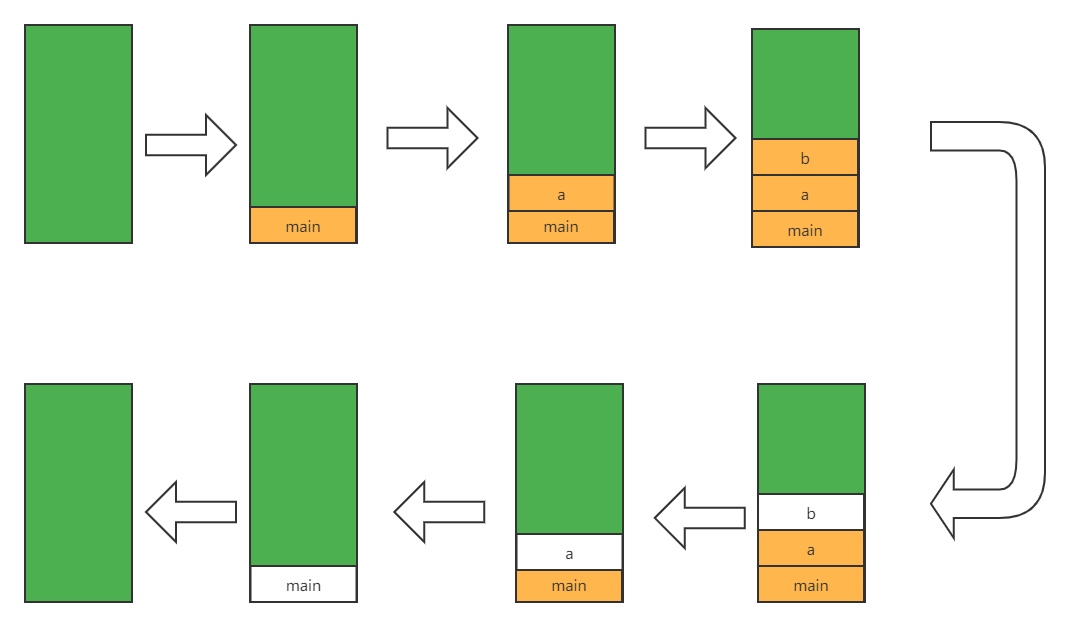
我们都知道,Java 程序的入口都是 main 方法开始的,因此当代码被执行时,会先调用 main 方法。不过,在调用 main 方法之前,JVM 创建一个方法栈,用来保存「当前线程」方法调用过程(因此方法栈是线程私有的)。于是方法栈中会放入第一个栈帧 main,由于栈结构的特性,main 自然而然的就会在栈底。
接着执行 main 方法,执行到最后需要调用 a 方法,因此将栈帧 a 放入方法栈中。接着 a 中又调用 b 方法,以此类推。现在,方法栈中已经有 3 个栈帧了,方法调用已经结束了。于是从栈顶开始,将方法的执行结果依次返回,b 方法中无返回值,因此执行完打印语句,b 栈帧就销毁了。以此类推到 a 方法,最后到 main,这就是上述代码玩完整的执行过程,流程如图:
了解了方法调用的基本流程,这里有几个疑问:
Q:当方法栈满了会发生什么?
A:当栈深度过⼤时抛出 StackOverflowError,著名的程序员交流网站就是以此命名的 stackoverflow
Q:栈帧销毁什么时候被销毁?
A:这些情况栈帧会被销毁:当方法执行抛出异常或者错误;方法正常返回结果或者无返回。
参数传递
来看一段简单的代码, a 方法定义了一个变量,并且调用了 b 方法使得该变量自增,然后打印该变量。
1 | |
a 方法中打印的结果为 0,按照正常的思维去理解的话,i 的值因该为 1 才对,这是为什么?
这是因为这些变量在方法中都是「值传递」的,当把 i 传递给 b 方法时,发生了一次拷贝,因此 b 方法中操作的 i,实际上只存在 b 方法中,并不会影响到 a 方法中的 i 变量。
上面说的是基本类型变量传递,接下来用引用数据类型来进行参数传递,看看发生了什么:
1 | |
a 方法中初始化了一个变量 obj,并把它当作参数传递给 b 方法,b 方法中创建一个新的对象,并把该对象地址赋值给参数 obj。整个过程就是这样,此时 a 中的 obj 对象和 b 中的 obj 是什么关系?他们是同一个对象吗?b 中的对象改变了,会影响到 a 吗?
有过编程经验的应该都知道,答案是否定的。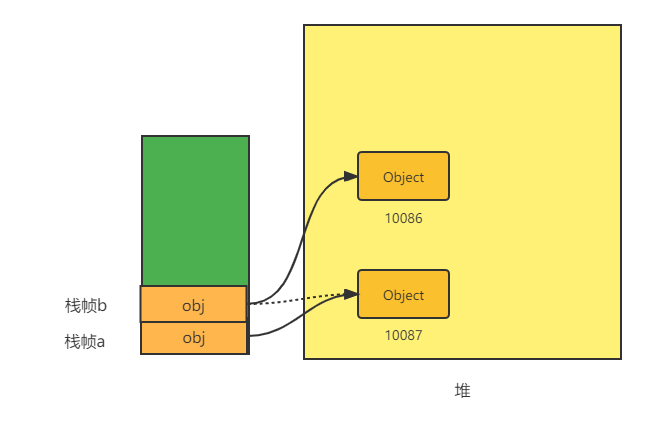
如图所示,a 中 obj 变量指向 Object 10087,把 obj 当作参数给 b 方法时,他会直接复制 obj 所指向的对象地址,即 b 方法刚开始也指向 10087 对象。之后创建了一个新对象地址为 10086,并把地址重新赋值给了 obj,因此 b 中的 obj 指向的是 10086,而 a 指向的是 10087,两者操作的都不是同一个对象,因此也不会相互影响。
栈帧
现在已经对 JVM 中的堆和栈有所了解,但是对于方法栈中的每个栈帧还不了解,目前只是知道方法调用就入栈,结束就出栈。因此,现在将栈帧放大来看,看看代码执行过程中,栈帧发生了什么。
每个栈帧中都有一个「操作数栈」和「局部变量表」。
每当方法调用开始的时候,局部变量表会被初始化成当前方法的参数。操作数栈上会根据代码实际情况,加载局部变量表中的数据,或者直接加载常量,根据字节码指令集,完成相应的数据操作。
这就像是人在吃饭一样,用筷子在碟子(局部变量表)中夹菜,夹到碗中(操作数栈),然后根据自己喜好(代码)吃自己的菜。
JVM 方法区
方法区中包含了整个虚拟机所共享的 Class 信息,JVM 就是根据方法区中 Class 这份说明书,来帮我们生成对象的。
方法区中存的所有信息都是共享,基本都是只读的,但这并不是一定的。「运行时常量池」就是个例外,在程序运行时往往会往常量池中放入常量信息。
运行时常量池会保存经常使用的常量,例如 String 字符串常量,当重复 new 一个相同字符串对象时,新的对象就会指向字符串常量池中的字符串常量,这样就节省了内存开销。同时在 String api 中,由于常量的重复使用,可以使得它的 equals 方法可以更快速地进行判断。
永久代和元空间
JVM 方法区是一块所有的线程共享的区域,是 JVM 所定义的规范。
Java 7 之前发方法区的实现称作「永久代」,即 PermGen。Java 8 之后的称作「元空间」,即 Metaspace。
在 Java 7 中,方法区和堆是使用一块连续的物理内存,仅仅是在逻辑上分开的。如果没有设置方法区的大小的话,使用默认大小很容易遇到 OOM 错误。
在 Java 8 之后,把方法区和堆区分开来,使用了本地内存(Native memory),大小取决于本地内存大小。